Difference between revisions of "Aufgaben:Exercise 3.10Z: BSC Channel Capacity"
| Line 4: | Line 4: | ||
[[File:P_ID2789__Inf_Z_3_9.png|right|frame|Entropien der Modelle „BC” und „BSC”]] | [[File:P_ID2789__Inf_Z_3_9.png|right|frame|Entropien der Modelle „BC” und „BSC”]] | ||
| − | Die Kanalkapazität $C$ wurde von [https://en.wikipedia.org/wiki/Claude_Shannon Claude E. Shannon] als die maximale Transinformation definiert, wobei sich die Maximierung allein auf die Quellenstatistik bezieht: | + | Die Kanalkapazität $C$ wurde von [https://en.wikipedia.org/wiki/Claude_Shannon Claude E. Shannon] als die maximale Transinformation definiert, wobei sich die Maximierung allein auf die Quellenstatistik bezieht: |
:$$ C = \max_{P_X(X)} \hspace{0.15cm} I(X;Y) \hspace{0.05cm}$$ | :$$ C = \max_{P_X(X)} \hspace{0.15cm} I(X;Y) \hspace{0.05cm}$$ | ||
| − | Beim Binärkanal mit der Wahrscheinlichkeitsfunktion $P_X(X) = \big [p_0, \ p_1 \big]$ ist nur ein Parameter optimierbar, beispielsweise $p_0$. Die Wahrscheinlichkeit für eine $1$ ist damit ebenfalls festgelegt: $p_1 = 1 - p_0.$ | + | Beim Binärkanal mit der Wahrscheinlichkeitsfunktion $P_X(X) = \big [p_0, \ p_1 \big]$ ist nur ein Parameter optimierbar, beispielsweise $p_0$. Die Wahrscheinlichkeit für eine $1$ ist damit ebenfalls festgelegt: $p_1 = 1 - p_0.$ |
| − | Die obere Grafik ( | + | Die obere Grafik (rötlich hinterlegt) fasst die Ergebnisse für den [[Informationstheorie/Anwendung_auf_die_Digitalsignalübertragung#Kanalkapazit.C3.A4t_eines_Bin.C3.A4rkanals|unsymmetrischen Binärkanal]] mit $ε_0 = 0.01$ und $ε_1 = 0.2$ zusammen, der auch im Theorieteil betrachtet wurde. |
| − | Die Maximierung führt zum Ergebnis $p_0 = 0.55$ ⇒ $p_1 = 0.45$, und man erhält für die Kanalkapazität: | + | Die Maximierung führt zum Ergebnis $p_0 = 0.55$ ⇒ $p_1 = 0.45$, und man erhält für die Kanalkapazität: |
:$$C_{\rm BC} = \hspace{-0.05cm} \max_{P_X(X)} \hspace{0.1cm} I(X;Y) \big |_{p_0 \hspace{0.05cm} = \hspace{0.05cm}0.55} \hspace{0.05cm}=\hspace{0.05cm} 0.5779\,{\rm bit} \hspace{0.05cm}.$$ | :$$C_{\rm BC} = \hspace{-0.05cm} \max_{P_X(X)} \hspace{0.1cm} I(X;Y) \big |_{p_0 \hspace{0.05cm} = \hspace{0.05cm}0.55} \hspace{0.05cm}=\hspace{0.05cm} 0.5779\,{\rm bit} \hspace{0.05cm}.$$ | ||
| − | In der unteren Grafik (blaue Hinterlegung) sind die gleichen informationstheoretischen Größen für den symmetrischen Kanal ⇒ [[Kanalcodierung/Kanalmodelle_und_Entscheiderstrukturen#Binary_Symmetric_Channel_.E2.80.93_BSC|Binary Symmetric Channel]] (BSC) mit den Verfälschungswahrscheinlichkeiten $ε_1 | + | In der unteren Grafik (blaue Hinterlegung) sind die gleichen informationstheoretischen Größen für den symmetrischen Kanal ⇒ [[Kanalcodierung/Kanalmodelle_und_Entscheiderstrukturen#Binary_Symmetric_Channel_.E2.80.93_BSC|Binary Symmetric Channel]] (BSC) mit den Verfälschungswahrscheinlichkeiten $ε_0 = ε_1 = ε = 0.1$ angegeben, der auch für die [[Aufgaben:3.10_Transinformation_beim_BSC| Aufgabe 3.10]] vorausgesetzt wurde. |
| − | In der vorliegenden Aufgabe sollen Sie für das BSC–Kanalmodell (zunächst für $ε = 0.1$ | + | In der vorliegenden Aufgabe sollen Sie für das BSC–Kanalmodell $($zunächst für $ε = 0.1)$ |
| − | :* die Entropien $H(X)$, $H(Y)$, $H(X|Y)$ | + | :* die Entropien $H(X)$, $H(Y)$, $H(X|Y)$ und $H(Y|X)$ analysieren, |
:* den Quellenparameter $p_0$ hinsichtlich maximaler Transinformation $I(X; Y)$ optimieren, | :* den Quellenparameter $p_0$ hinsichtlich maximaler Transinformation $I(X; Y)$ optimieren, | ||
:* somit die Kanalkapazität $C(ε)$ bestimmen, sowie | :* somit die Kanalkapazität $C(ε)$ bestimmen, sowie | ||
| Line 37: | Line 37: | ||
{ Welche Aussagen gelten für die bedingten Entropien beim BSC–Modell? | { Welche Aussagen gelten für die bedingten Entropien beim BSC–Modell? | ||
|type="[]"} | |type="[]"} | ||
| − | - Die Äquivokation ergibt sich zu $H(X|Y) = H_{\rm bin}(ε)$. | + | - Die Äquivokation ergibt sich zu $H(X|Y) = H_{\rm bin}(ε)$. |
| − | + Die Irrelevanz ergibt sich zu $H(Y|X) = H_{\rm bin}(ε)$. | + | + Die Irrelevanz ergibt sich zu $H(Y|X) = H_{\rm bin}(ε)$. |
| − | - Die Irrelevanz ergibt sich zu $H(Y|X) = H_{\rm bin}(p_0)$. | + | - Die Irrelevanz ergibt sich zu $H(Y|X) = H_{\rm bin}(p_0)$. |
| − | {Welche Aussagen gelten für die Kanalkapazität $C_{\rm BSC}$ des BSC–Modells? | + | {Welche Aussagen gelten für die Kanalkapazität $C_{\rm BSC}$ des BSC–Modells? |
|type="[]"} | |type="[]"} | ||
+ Die Kanalkapazität ist gleich der maximalen Transinformation. | + Die Kanalkapazität ist gleich der maximalen Transinformation. | ||
+ Die Maximierung führt beim BSC zum Ergebnis $p_0 = p_1 = 0.5$. | + Die Maximierung führt beim BSC zum Ergebnis $p_0 = p_1 = 0.5$. | ||
| − | + Für $p_0 = p_1 = 0.5$ gilt $H(X) = H(Y) = 1 \ \rm bit$. | + | + Für $p_0 = p_1 = 0.5$ gilt $H(X) = H(Y) = 1 \ \rm bit$. |
| − | {Welche Kanalkapazität $C_{\rm BSC}$ ergibt sich abhängig vom BSC–Parameter $ε$? | + | {Welche Kanalkapazität $C_{\rm BSC}$ ergibt sich abhängig vom BSC–Parameter $ε$? |
|type="{}"} | |type="{}"} | ||
$ε = 0.0\text{:} \hspace{0.5cm} C_{\rm BSC} \ = \ $ { 1 1% } $\ \rm bit$ | $ε = 0.0\text{:} \hspace{0.5cm} C_{\rm BSC} \ = \ $ { 1 1% } $\ \rm bit$ | ||
| Line 53: | Line 53: | ||
$ε = 0.5\text{:} \hspace{0.5cm} C_{\rm BSC} \ = \ $ { 0. } $\ \rm bit$ | $ε = 0.5\text{:} \hspace{0.5cm} C_{\rm BSC} \ = \ $ { 0. } $\ \rm bit$ | ||
| − | {Welche Kanalkapazität $C_{\rm BSC}$ ergibt sich abhängig vom BSC–Parameter $ε$? | + | {Welche Kanalkapazität $C_{\rm BSC}$ ergibt sich abhängig vom BSC–Parameter $ε$? |
|type="{}"} | |type="{}"} | ||
$ε = 1.0\text{:} \hspace{0.5cm} C_{\rm BSC} \ = \ $ { 1 1% } $\ \rm bit$ | $ε = 1.0\text{:} \hspace{0.5cm} C_{\rm BSC} \ = \ $ { 1 1% } $\ \rm bit$ | ||
Revision as of 15:17, 3 February 2020

Die Kanalkapazität $C$ wurde von Claude E. Shannon als die maximale Transinformation definiert, wobei sich die Maximierung allein auf die Quellenstatistik bezieht:
- $$ C = \max_{P_X(X)} \hspace{0.15cm} I(X;Y) \hspace{0.05cm}$$
Beim Binärkanal mit der Wahrscheinlichkeitsfunktion $P_X(X) = \big [p_0, \ p_1 \big]$ ist nur ein Parameter optimierbar, beispielsweise $p_0$. Die Wahrscheinlichkeit für eine $1$ ist damit ebenfalls festgelegt: $p_1 = 1 - p_0.$
Die obere Grafik (rötlich hinterlegt) fasst die Ergebnisse für den unsymmetrischen Binärkanal mit $ε_0 = 0.01$ und $ε_1 = 0.2$ zusammen, der auch im Theorieteil betrachtet wurde.
Die Maximierung führt zum Ergebnis $p_0 = 0.55$ ⇒ $p_1 = 0.45$, und man erhält für die Kanalkapazität:
- $$C_{\rm BC} = \hspace{-0.05cm} \max_{P_X(X)} \hspace{0.1cm} I(X;Y) \big |_{p_0 \hspace{0.05cm} = \hspace{0.05cm}0.55} \hspace{0.05cm}=\hspace{0.05cm} 0.5779\,{\rm bit} \hspace{0.05cm}.$$
In der unteren Grafik (blaue Hinterlegung) sind die gleichen informationstheoretischen Größen für den symmetrischen Kanal ⇒ Binary Symmetric Channel (BSC) mit den Verfälschungswahrscheinlichkeiten $ε_0 = ε_1 = ε = 0.1$ angegeben, der auch für die Aufgabe 3.10 vorausgesetzt wurde.
In der vorliegenden Aufgabe sollen Sie für das BSC–Kanalmodell $($zunächst für $ε = 0.1)$
- die Entropien $H(X)$, $H(Y)$, $H(X|Y)$ und $H(Y|X)$ analysieren,
- den Quellenparameter $p_0$ hinsichtlich maximaler Transinformation $I(X; Y)$ optimieren,
- somit die Kanalkapazität $C(ε)$ bestimmen, sowie
- durch Verallgemeinerung eine geschlossene Gleichung für $C(ε)$ angeben.
Hinweise:
- Die Aufgabe gehört zum Kapitel Anwendung auf die Digitalsignalübertragung.
- Bezug genommen wird insbesondere auf die Seite Kanalkapazität eines Binärkanals.
Fragebogen
Musterlösung
- $$H(Y \hspace{-0.1cm}\mid \hspace{-0.1cm} X) = p_0 \cdot (1 - \varepsilon) \cdot {\rm log}_2 \hspace{0.1cm} \frac{1}{1 - \varepsilon} + p_0 \cdot \varepsilon \cdot {\rm log}_2 \hspace{0.1cm} \frac{1}{\varepsilon} +p_1 \cdot \varepsilon \cdot {\rm log}_2 \hspace{0.1cm} \frac{1}{\varepsilon} + p_1 \cdot (1 - \varepsilon) \cdot {\rm log}_2 \hspace{0.1cm} \frac{1}{1 - \varepsilon} $$
- $$\Rightarrow \hspace{0.3cm} H(Y \hspace{-0.1cm}\mid \hspace{-0.1cm} X) = (p_0 + p_1) \cdot \left [ \varepsilon \cdot {\rm log}_2 \hspace{0.1cm} \frac{1}{\varepsilon} + (1 - \varepsilon) \cdot {\rm log}_2 \hspace{0.1cm} \frac{1}{1 - \varepsilon} \right ] \hspace{0.05cm}.$$
- Mit $p_0 + p_1 = 1$ und der binären Entropiefunktion $H_{\rm bin}$ erhält man das vorgeschlagene Ergebnis: $H(Y \hspace{-0.1cm}\mid \hspace{-0.1cm} X) = H_{\rm bin}(\varepsilon)\hspace{0.05cm}.$
- Für $ε = 0.1$ ergibt sich $H(Y|X) = 0.4690 \ \rm bit$. Der gleiche Wert steht für alle $p_0$ in der vorgegebenen Tabelle.
- Aus der Tabelle erkennt man auch, dass beim BSC–Modell (blaue Hinterlegung) wie auch beim allgemeineren (unsymmetrischen) BC–Modell (rote Hinterlegung) die Äquivokation $H(X|Y)$ von den Quellensymbolwahrscheinlichkeiten $p_0$ und $p_1$ abhängen. Daraus folgt, dass der Lösungsvorschlag 1 nicht richtig sein kann.
- Die Irrelevanz $H(Y|X)$ istunabhängig von der Quellenstatistik, so dass auch der Lösungsvorschlag 3 ausgeschlossen werden kann.
(2) Zutreffend sind hier alle vorgegebenen Lösungsalternativen:
- Die Kanalkapazität ist definiert als die maximale Transinformation, wobei die Maximierung hinsichtlich $P_X = (p_0, p_1)$ zu erfolgen hat:
- $$C = \max_{P_X(X)} \hspace{0.15cm} I(X;Y) \hspace{0.05cm}.$$
- Die Gleichung gilt allgemein, also auch für den rot hinterlegten unsymmetrischen Binärkanal.
- Die Transinformation kann zum Beispiel berechnet werden als $I(X;Y) = H(Y) - H(Y \hspace{-0.1cm}\mid \hspace{-0.1cm} X)\hspace{0.05cm}$, wobei entsprechend der Teilaufgabe (1) der Term $H(Y \hspace{-0.1cm}\mid \hspace{-0.1cm} X)\hspace{0.05cm}$ unabhängig von $p_0$ bzw. $p_1 = 1- p_0$ ist.
- Die maximale Transinformation ergibt sich somit genau dann, wenn die Sinkenentropie $H(Y)$ maximal ist. Dies ist der Fall für $p_0 = p_1 = 0.5$ ⇒ $H(X) = H(Y) = 1 \ \rm bit$.
(3) Entsprechend den Teilaufgaben (1) und (2) erhält man für die BSC–Kanalkapazität:
- $$C = \max_{P_X(X)} \hspace{0.15cm} I(X;Y) \hspace{0.05cm}.$$
Die Grafik zeigt links die binäre Entropiefunktion und rechts die Kanalkapazität. Man erhält:
- für $ε = 0$ (fehlerfreier Kanal): $C = 1\ \rm (bit)$ ⇒ Punkt mit gelber Füllung,
- für $ε = 0.1$ (bisher betrachtet): $C = 0.531\ \rm (bit)$ ⇒ Punkt mit grüner Füllung,
- für $ε = 0.5$ (vollkommen gestört): $C = 0\ \rm (bit)$ ⇒ Punkt mit grauer Füllung.
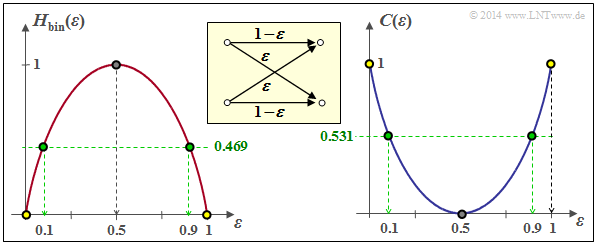 Binäre Entropiefunktion und BSC–Kanalkapazität
Binäre Entropiefunktion und BSC–Kanalkapazität

(4) Aus der Grafik erkennt man, dass aus informationstheoretischer Sicht $ε = 1$ identisch mit $ε = 0$ ist:
- $$C_{\rm BSC} \big |_{\hspace{0.05cm}\varepsilon \hspace{0.05cm} = \hspace{0.05cm}1} \hspace{0.05cm}= C_{\rm BSC} \big |_{\hspace{0.05cm}\varepsilon \hspace{0.05cm} = \hspace{0.05cm}0} \hspace{0.15cm} \underline {=1\,{\rm (bit)}} \hspace{0.05cm}$$
- Der Kanal nimmt hier nur eine Umbenennung vor. Man spricht von „Mapping”.
- Aus jeder $0$ wird eine $1$ und aus jeder $1$ eine $0$. Entsprechend gilt:
- $$C_{\rm BSC} \big |_{\hspace{0.05cm}\varepsilon \hspace{0.05cm} = \hspace{0.05cm}0.9} \hspace{0.05cm}= C_{\rm BSC} \big |_{\hspace{0.05cm}\varepsilon \hspace{0.05cm} = \hspace{0.05cm}0.1} \hspace{0.15cm} \underline {=0.531\,{\rm (bit)}} \hspace{0.05cm}$$