[[File:P_ID2589__KC_Z_3_1.png|right|frame|Zwei Faltungscodes der Rate 1/2]]
[[File:EN_KC_Z_3_1_jetztaber.png|right|frame|Convolutional codes of rate $1/2$]]
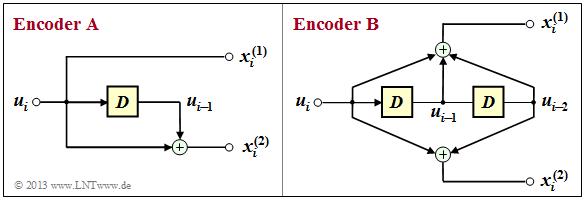
Die Grafik zeigt zwei Faltungscodierer der Rate $R = 1/2$. Am Eingang liegt die Informationssequenz $\underline {u} = (u_1, u_2, \ ... \ , u_i, \ ...$) an. Hieraus werden durch Modulo–2–Operationen die beiden Sequenzen
The graphic shows two convolutional encoders of rate $R = 1/2$:
erzeugt, wobei $x_i^{(j)}$ mit $j = 1$ bzw. $j = 2$ außer von $u_i$ auch von den vorherigen Informationsbits $u_{i–1}, \ ... \ , u_{i \, –m}$ abhängen kann. Man bezeichnet $m$ als das Gedächtnis und $\nu = m + 1$ als die Einflusslänge des Codes bzw. des Codierers. Die betrachteten Coder <span style="color: rgb(204, 0, 0);"><b>A</b></span> und <span style="color: rgb(204, 0, 0);"><b>B</b></span> unterscheiden sich hinsichtlich dieser Größen.
*From this, modulo-2 operations generate the two sequences
In der Grafik nicht dargestellt ist das Multiplexen der beiden Teilsequenzen $\underline {x}^{(1)}$ und $\underline {x}^{(2)}$ zur resultierenden Codesequenz $\underline {x} = (x_1^{(1)}, x_1^{(2)}, x_2^{(1)}, x_2^{(2)}, \ ...)$.
:where $x_i^{(j)}$ with $j = 1$ resp. $j = 2$ may depend except from $u_i$ also from the previous information bits $u_{i-1}, \ \text{...} \ , u_{i-m}$.
In den Teilaufgaben (3) bis (5) sollen Sie den jeweiligen Beginn der Sequenzen $\underline {x}^{(1)}, \underline{x}^{(2)}$ und $\underline{x}$ ermitteln, wobei von der Informationssequenz $\underline{u} = (1, 0, 1, 1, 0, 0, \ ...)$ auszugehen ist.
*One refers $m$ as the "memory" and $\nu = m + 1$ as the "influence length" of the code $($or of the encoder$)$.
''Hinweise:''
* The considered encoders $\rm A$ and $\rm B$ differ with respect to these quantities.
* Die Aufgabe bezieht sich auf das Themengebiet des Kapitels [[Kanalcodierung/Grundlagen_der_Faltungscodierung| Grundlagen der Faltungscodierung]].
* Sollte die Eingabe des Zahlenwertes „0” erforderlich sein, so geben Sie bitte „0.” ein.$$
===Fragebogen===
<u>Hints:</u>
*The exercise refers to the chapter [[Channel_Coding/Basics_of_Convolutional_Coding| "Basics of Convolutional Coding"]].
*Not shown in the diagram is the multiplexing of the two subsequences $\underline {x}^{(1)}$ and $\underline {x}^{(2)}$ to the resulting code sequence
*In subtasks '''(3)''' to '''(5)''' you are to determine the start of the sequences $\underline {x}^{(1)}, \underline{x}^{(2)}$ and $\underline{x}$ assuming the information sequence
'''(1)''' For both encoders, $k = 1$ and $n = 2$.
'''(2)'''
'''(3)'''
*The memory $m$ and the influence length $\nu$ are different ⇒ <u>Answers 3 and 4</u>.
'''(4)'''
'''(5)'''
'''(2)''' The shift register of encoder $\rm A$ does contain two memory cells. However, since $x_i^{(1)} = u_i$ and $x_i^{(2)} = u_i + u_{i-1}$ is influenced only by the immediately preceding bit $u_{i-1}$ besides the current information bit $u_i$,
*The <u>proposed solution 1</u> is correct. The second solution suggestion ⇒ $\underline {x}^{(1)} = \underline {u}$ would only be valid for a systematic code $($which is not present here$)$.
*A comparison with the solutions of subtasks '''(3)''' and '''(4)''' shows the correctness of the <u>proposed solution 1</u>.
{{ML-Fuß}}
{{ML-Fuß}}
[[Category:Aufgaben zu Kanalcodierung|^3.1 Grundlagen der Faltungscodierung^]]
[[Category:Channel Coding: Exercises|^3.1 Basics of Convolutional Coding^]]
[[de:Aufgaben:Aufgabe 3.1Z: Faltungscodes der Rate 1/2]]
In subtasks (3) to (5) you are to determine the start of the sequences $\underline {x}^{(1)}, \underline{x}^{(2)}$ and $\underline{x}$ assuming the information sequence
The memory $m$ and the influence length $\nu$ are different ⇒ Answers 3 and 4.
(2) The shift register of encoder $\rm A$ does contain two memory cells. However, since $x_i^{(1)} = u_i$ and $x_i^{(2)} = u_i + u_{i-1}$ is influenced only by the immediately preceding bit $u_{i-1}$ besides the current information bit $u_i$,
Equivalent encoder representations
the memory is $m = 1$, and
the influence length is $\nu = m + 1 = 2$.
The graphic shows the two encoders in another representation, whereby the "memory cells" are highlighted in yellow.
For the encoder $\rm A$ one recognizes only one memory ⇒ $m = 1$.
In contrast, for the encoder $\rm B$ actually $m = 2$ and $\nu = 3$.
Thus, the proposed solution 2 is correct.
(3) For the upper output of encoder $\rm B$ applies in general:
The proposed solution 1 is correct. The second solution suggestion ⇒ $\underline {x}^{(1)} = \underline {u}$ would only be valid for a systematic code $($which is not present here$)$.