{Welche Aussagen gelten für den Block $\rm BWT$ des Codiersystems?
{Which statements are true for block $\rm BWT$ of the coding system?
|type="[]"}
|type="[]"}
+ Die Eingangszeichenmenge ist $\{ \hspace{0.05cm}\rm D,\hspace{0.05cm} E,\hspace{0.05cm} I,\hspace{0.05cm} M,\hspace{0.05cm} N , \hspace{0.05cm} S \}$.
+ The input character set is $\{ \hspace{0.05cm}\rm D,\hspace{0.05cm} E,\hspace{0.05cm} I,\hspace{0.05cm} M,\hspace{0.05cm} N , \hspace{0.05cm} S \}$.
+ Die Ausgangszeichenmenge ist $\{ \hspace{0.05cm}\rm D,\hspace{0.05cm} E,\hspace{0.05cm} I,\hspace{0.05cm} M,\hspace{0.05cm} N , \hspace{0.05cm} S \}$.
+ The output character set is $\{ \hspace{0.05cm}\rm D,\hspace{0.05cm} E,\hspace{0.05cm} I,\hspace{0.05cm} M,\hspace{0.05cm} N , \hspace{0.05cm} S \}$.
- In der Ausgangsfolge treten alle $M = 6$ Zeichen gruppiert auf.
- In the output sequence, allnbsp; $M = 6$ characters occur grouped together.
{Welche Aussagen gelten für den Block $\rm MTF$ des Codiersystems?
{Which statements are true for the block $\rm MTF$ of the coding system?
|type="[]"}
|type="[]"}
- Die Ausgangszeichenmenge ist $\{ \hspace{0.05cm}\rm D,\hspace{0.05cm} E,\hspace{0.05cm} I,\hspace{0.05cm} M,\hspace{0.05cm} N , \hspace{0.05cm} S \}$.
- The output character set is $\{ \hspace{0.05cm}\rm D,\hspace{0.05cm} E,\hspace{0.05cm} I,\hspace{0.05cm} M,\hspace{0.05cm} N , \hspace{0.05cm} S \}$.
- The best would be $\rm Pr(0) ≈ Pr(1) ≈ \text{...} ≈ Pr(5)$.
{Welche Aussagen gelten für den abschließenden Block "Huffman"?
{Which statements are true for the final block "Huffman"?
|type="[]"}
|type="[]"}
+ Die Ausgangsfolge ist binär.
+ The initial sequence is binary.
+ Er bewirkt eine möglichst kleine mittlere Codewortlänge.
+ It causes the smallest possible average codeword length.
+ Die Dimensionierung richtet sich nach den anderen Blöcken.
+ The dimensioning depends on the other blocks.
Line 70:
Line 70:
</quiz>
</quiz>
===Musterlösung===
===Solutions===
{{ML-Kopf}}
{{ML-Kopf}}
'''(1)''' Die Grafik auf der Angabenseite zeigt, dass die <u>Lösungsvorschläge 1 und 2</u> richtig sind und der Vorschlag 3 falsch ist:
'''(1)''' The graph on the information page shows that <u>solution suggestions 1 and 2</u> are correct and suggestion 3 is incorrect:
*$\rm E$ und $\rm I$ treten zwar gruppiert auf,
*$\rm E$ und $\rm I$ treten zwar gruppiert auf,
*aber nicht die $\rm N$–Zeichen.
*aber nicht die $\rm N$–Zeichen.
'''(2)''' Richtig sind die <u>Lösungsvorschläge 2 und 3</u>:
'''(2)''' <u>Proposed solutions 2 and 3</u> are correct:
*Die Eingangsfolge wird Zeichen für Zeichen abgearbeitet. Auch die Ausgangsfolge hat somit die Länge $N = 12$.
*The input sequence is processed character by character. Thus, the output sequence also has the length $N = 12$.
*Tatsächlich wird die Eingangsmenge $\{ \hspace{0.05cm}\rm D,\hspace{0.05cm} E,\hspace{0.05cm} I,\hspace{0.05cm} M,\hspace{0.05cm} N , \hspace{0.05cm} S \}$ in die Ausgangsmenge $\{ \hspace{0.05cm}\rm 0,\hspace{0.05cm} 1,\hspace{0.05cm} 2,\hspace{0.05cm} 3,\hspace{0.05cm} 4 , \hspace{0.05cm} 5 \}$ gewandelt.
*In fact, the input set $\{ \hspace{0.05cm}\rm D,\hspace{0.05cm} E,\hspace{0.05cm} I,\hspace{0.05cm} M,\hspace{0.05cm} N , \hspace{0.05cm} S \}$ in die Ausgangsmenge $\{ \hspace{0.05cm}\rm 0,\hspace{0.05cm} 1,\hspace{0.05cm} 2,\hspace{0.05cm} 3,\hspace{0.05cm} 4 , \hspace{0.05cm} 5 \}$ is converted into the output set.
*Allerdings nicht durch einfaches <i>Mapping</i>, sondern durch einen Algorithmus, der nachfolgend skizziert wird.
*However, not by simple <i>mapping</i>, but by an algorithm which is outlined below.
[[File:EN_Inf_Z_2_14.png|center|frame|Beispiel für den MTF–Algorithmus]]
[[File:EN_Inf_Z_2_14.png|center|frame|Example of the MTF algorithm]]
'''(3)''' Richtig ist der <u>Lösungsvorschlag 2</u>:
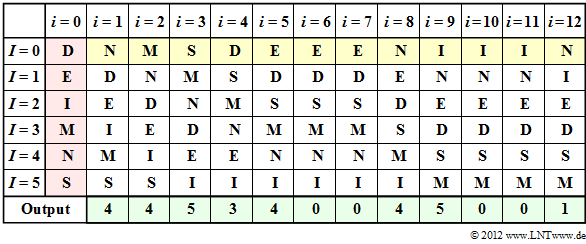
'''(3)''' Correct is <u>solution suggestion 2</u>:
*Die Tabelle zeigt den MTF–Algorithmus. Der Schritt $i=0$ (rote Hinterlegung) gibt die Vorbelegung an. Die Eingabe der MTF ist gelb hinterlegt, die Ausgabe grün.
*The table shows the MTF algorithm. The step $i=0$ (red background) indicates the preassignment. The input of the MTF is highlighted in yellow, the output in green.
* Im Schritt $i=1$ wird das Eingangszeichen $\rm N$ entsprechend der Spalte $i=0$ durch den Index $I = 4$ dargestellt. Anschließend wird $\rm N$ nach vorne sortiert, während die Reihenfolge der anderen Zeichen gleich bleibt.
* In step $i=1$ , the input character $\rm N$ corresponding to column $i=0$ is represented by index $I = 4$ . Subsequently, $\rm N$ is sorted to the front, while the order of the other characters remains the same.
* Das Eingangszeichen $\rm M$ im zweiten Schritt erhält entsprechend der Spalte $i=2$ ebenfalls den Index $I = 4$. In gleicher Weise macht man weiter bis zum zwölften Zeichen $\rm N$, dem der Index $I = 1$ zugeordnet wird.
*The input character $\rm M$ in the second step is also given the index $I = 4$ according to column $i=2$ . One continues in the same way until the twelfth character $\rm N$, to which the index $I = 1$ is assigned.
*Man erkennt aus obiger Tabelle weiter, dass zu den Zeitpunkten $i=6$, $i=7$, $i=10$ und $i=11$ der Ausgabeindex jeweils $I = 0$ ist.
*You can see from the above table that at the times $i=6$, $i=7$, $i=10$ and $i=11$ the output index is $I = 0$ .
'''(4)''' Richtig sind die <u>Aussagen 1 und 2</u>:
'''(4)''' <u>Statements 1 and 2</u> are correct:
*Die Vorverarbeitungen "BWT" und "MTF" haben nur die Aufgabe, möglichst viele Nullen zu generieren.
*The preprocessings "BWT" and "MTF" only have the task to generate as many zeros as possible.
'''(5)''' <u>Alle Aussagen</u> sind richtig.
'''(5)''' <u>All statements</u> are correct.
*Nähere Angaben zum Huffman–Algorithmus finden Sie im Kapitel "Entropiecodierung nach Huffman".
*You can find more information on the Huffman algorithm in the chapter "Entropy coding according to Huffman".
{{ML-Fuß}}
{{ML-Fuß}}
[[Category:Information Theory: Exercises|^2.4 Further Source Coding Methods^]]
[[Category:Information Theory: Exercises|^2.4 Further Source Coding Methods^]]
Burrows–Wheeler–Transformation $\rm (BWT)$ as described in Exercise 2.13; the two character sets at the input and output of the BWT are the same: $\{$ $\rm D$, $\rm E$, $\rm I$, $\rm M$, $\rm N$, $\rm S$ $\}$;
Move–to–Front $\rm (MTF)$, a sorting algorithm that outputs a string of the same length $($ $N = 12 in the example)$, but with a different alphabet $\{$0, 1, 2, 3, 4, 5$\}$ ;
$\rm RLC0$ – a run-length encoding specifically for zero, which is (as) frequent according to $\rm BWT$ and $\rm MTF$ ; all other indices are not changed by $\rm RLC0$ ;
$\rm Huffman$ as described in the chapter Entropy coding according to Huffman; frequent characters are represented by short binary sequences and rare ones by long ones.
The $\rm MTF$–algorithm can be described as follows for $M = 6$ input symbols:
The output sequence of the $\rm MTF$ is a string of indices from the set
$ I = \{$0, 1, 2, 3, 4, 5$\}$.
Before starting the actual $\rm MTF$ algorithm, the possible input symbols are sorted lexicographically and assigned to the following indices:
Let the $\rm MTF$ input string here be $\rm N\hspace{0.05cm}M\hspace{0.05cm}S\hspace{0.05cm}D\hspace{0.05cm}E\hspace{0.05cm}E\hspace{0.05cm}E\hspace{0.05cm}N\hspace{0.05cm}I\hspace{0.05cm}I\hspace{0.05cm}I\hspace{0.05cm}N$. This was the $\rm BWT$ result in Exercise 2.13. The first $\rm N$ is represented as $I = 4$ according to the default setting.
Then the $\rm N$ is placed at the beginning in the sorting, so that after the coding step $i = 1$ the assignment holds:
Information on the Huffman code can be found in the chapter Entropy Coding according to Huffman. This information is not necessary for the solution of the task.
(1) The graph on the information page shows that solution suggestions 1 and 2 are correct and suggestion 3 is incorrect:
$\rm E$ und $\rm I$ treten zwar gruppiert auf,
aber nicht die $\rm N$–Zeichen.
(2)Proposed solutions 2 and 3 are correct:
The input sequence is processed character by character. Thus, the output sequence also has the length $N = 12$.
In fact, the input set $\{ \hspace{0.05cm}\rm D,\hspace{0.05cm} E,\hspace{0.05cm} I,\hspace{0.05cm} M,\hspace{0.05cm} N , \hspace{0.05cm} S \}$ in die Ausgangsmenge $\{ \hspace{0.05cm}\rm 0,\hspace{0.05cm} 1,\hspace{0.05cm} 2,\hspace{0.05cm} 3,\hspace{0.05cm} 4 , \hspace{0.05cm} 5 \}$ is converted into the output set.
However, not by simple mapping, but by an algorithm which is outlined below.
Example of the MTF algorithm
(3) Correct is solution suggestion 2:
The table shows the MTF algorithm. The step $i=0$ (red background) indicates the preassignment. The input of the MTF is highlighted in yellow, the output in green.
In step $i=1$ , the input character $\rm N$ corresponding to column $i=0$ is represented by index $I = 4$ . Subsequently, $\rm N$ is sorted to the front, while the order of the other characters remains the same.
The input character $\rm M$ in the second step is also given the index $I = 4$ according to column $i=2$ . One continues in the same way until the twelfth character $\rm N$, to which the index $I = 1$ is assigned.
You can see from the above table that at the times $i=6$, $i=7$, $i=10$ and $i=11$ the output index is $I = 0$ .
(4)Statements 1 and 2 are correct:
The preprocessings "BWT" and "MTF" only have the task to generate as many zeros as possible.
(5)All statements are correct.
You can find more information on the Huffman algorithm in the chapter "Entropy coding according to Huffman".