Blockschaltbild und Voraussetzungen
Wir gehen von dem bereits im Kapitel Kanalmodelle und Entscheiderstrukturen gezeigten Blockschaltbild aus, wobei als Kanalmodell meist der Binary Symmetric Channel (BSC) verwendet wird. Zur Codewortschätzung verwenden wir den Maximum–Likelihood–Entscheider (ML), der für binäre Codes ⇒ $\underline{x} \in {\rm GF}(2^n)$ das gleiche Ergebnis liefert wie der MAP–Empfänger.

Die Aufgabe des Kanaldecoders kann wie folgt beschrieben werden:
- Der Vektor υ nach der Decodierung (an der Sinke) soll möglichst gut mit dem Informationswort u übereinstimmen. Das heißt: Die Blockfehlerwahrscheinlichkeit soll möglichst klein sein:
- [math]\displaystyle{ { \rm Pr(Blockfehler)} = { \rm Pr}( \underline{v} \ne \underline{u}) \stackrel{!}{=} { \rm Minimum}\hspace{0.05cm}. }[/math]
- Aufgrund der deterministischen Zuweisungen x = enc(u) bzw. υ = enc–1(z) gilt aber auch:
- [math]\displaystyle{ { \rm Pr(Blockfehler)} = { \rm Pr}( \underline{z} \ne \underline{x}) \stackrel{!}{=} { \rm Minimum}\hspace{0.05cm}. }[/math]
- Gesucht ist somit das zum gegebenen Empfangswort y = x + e am wahrscheinlichsten gesendete Codewort xi, das als Ergebnis z weiter gegeben wird:
- [math]\displaystyle{ \underline{z} = {\rm arg} \max_{\underline{x}_{\hspace{0.03cm}i} \hspace{0.05cm} \in \hspace{0.05cm} \mathcal{C}} \hspace{0.1cm} {\rm Pr}( \underline{x}_{\hspace{0.03cm}i} \hspace{0.05cm}|\hspace{0.05cm} \underline{y} ) \hspace{0.05cm}. }[/math]
- Beim BSC–Kanal gilt sowohl xi ∈ GF(2n) als auch y ∈ GF(2n), so dass die ML–Regel auch mit der Hamming–Distanz dH(y, xi) geschrieben werden kann:
- [math]\displaystyle{ \underline{z} = {\rm arg} \min_{\underline{x}_{\hspace{0.03cm}i} \hspace{0.05cm} \in \hspace{0.05cm} \mathcal{C}} \hspace{0.1cm} d_{\rm H}(\underline{y} \hspace{0.05cm}, \hspace{0.1cm}\underline{x}_{\hspace{0.03cm}i})\hspace{0.05cm}. }[/math]
Prinzip der Syndromdecodierung
Vorausgesetzt wird hier ein (n, k)–Blockcode mit der Prüfmatrix H und den systematischen Codeworten
- [math]\displaystyle{ \underline{x}\hspace{0.05cm} = (x_1, x_2, ... \hspace{0.05cm}, x_i, ... \hspace{0.05cm}, x_n) = (u_1, u_2, ... \hspace{0.05cm}, u_k, p_1, ... \hspace{0.05cm}, p_{n-k})\hspace{0.05cm}. }[/math]
Mit dem Fehlervektor e gilt dann für das Empfangswort:
- [math]\displaystyle{ \underline{y} = \underline{x} + \underline{e} \hspace{0.05cm}, \hspace{0.4cm} \underline{y} \in \hspace{0.1cm} {\rm GF}(2^n) \hspace{0.05cm}, \hspace{0.1cm} \underline{x} \in \hspace{0.1cm} {\rm GF}(2^n) \hspace{0.05cm}, \hspace{0.1cm} \underline{e} \in \hspace{0.1cm} {\rm GF}(2^n) \hspace{0.05cm}. }[/math]
Ein Bitfehler an der Position i, das heißt yi ≠ xi, wird ausgedrückt durch den Fehlerkoeffizienten ei = 1.
- [math]\displaystyle{ \underline{s} = \underline{y} \cdot { \boldsymbol{\rm H}}^{\rm T}\hspace{0.3cm}{\rm bzw.}\hspace{0.3cm} \underline{s}^{\rm T} = { \boldsymbol{\rm H}} \cdot \underline{y}^{\rm T}\hspace{0.05cm}. }[/math]
Das Syndrom s zeigt folgende Charakteristika:
- Wegen x · HT = 0 hängt s nicht vom Codewort x ab, sondern allein vom Fehlervektor e:
- [math]\displaystyle{ \underline{s} = \underline{y} \cdot { \boldsymbol{\rm H}}^{\rm T} = \hspace{0.05cm} \underline{x} \cdot { \boldsymbol{\rm H}}^{\rm T} + \hspace{0.05cm} \underline{e} \cdot { \boldsymbol{\rm H}}^{\rm T} = \hspace{0.05cm} \underline{e} \cdot { \boldsymbol{\rm H}}^{\rm T} \hspace{0.05cm}. }[/math]
- Bei hinreichend wenig Bitfehlern liefert s einen eindeutigen Hinweis auf die Fehlerpositionen und ermöglicht so eine vollständige Fehlerkorrektur.
- [math]\displaystyle{ { \boldsymbol{\rm H}} \cdot \underline{y}^{\rm T} = \begin{pmatrix} 1 &1 &1 &0 &1 &0 &0\\ 0 &1 &1 &1 &0 &1 &0\\ 1 &1 &0 &1 &0 &0 &1 \end{pmatrix} \cdot \begin{pmatrix} 0 \\ 1 \\ 1 \\ 1 \\ 0 \\ 0 \\ 1 \end{pmatrix} = \begin{pmatrix} 0 \\ 1 \\ 1 \end{pmatrix} = \underline{s}^{\rm T} \hspace{0.05cm}. }[/math]
Vergleicht man das Syndrom mit den Prüfgleichungen des Hamming–Codes, so erkennt man, dass
- am wahrscheinlichsten das vierte Symbol (x4 = u4) des Codewortes verfälscht wurde,
- der Codewortschätzer somit das Ergebnis z = (0, 1, 1, 0, 0, 0, 1) liefern wird.
- die Entscheidung nur dann richtig ist, wenn bei der Übertragung nur ein Bit verfälscht wurde.
Nachfolgend sind die erforderlichen Korrekturen für den (7, 4, 3)–Hamming–Code angegeben, die sich aus dem errechneten Syndrom s entsprechend den Spalten der Prüfmatrix ergeben:
- [math]\displaystyle{ \underline{s} \hspace{-0.15cm} = \hspace{-0.15cm} (0, 0, 0) \hspace{0.10cm} \Rightarrow\hspace{0.10cm}{\rm keine\hspace{0.15cm} Korrektur}\hspace{0.05cm};\hspace{0.4cm}\underline{s} = (1, 0, 0)\hspace{0.10cm} \Rightarrow\hspace{0.10cm}p_1{\rm \hspace{0.15cm} invertieren}\hspace{0.05cm}; }[/math]
- [math]\displaystyle{ \underline{s} \hspace{-0.15cm} = \hspace{-0.15cm}(0, 0, 1)\hspace{0.10cm} \Rightarrow\hspace{0.10cm} p_3{\rm \hspace{0.15cm} invertieren}\hspace{0.05cm};\hspace{0.82cm}\underline{s} = (1, 0, 1)\hspace{0.10cm} \Rightarrow\hspace{0.10cm} u_1{\rm \hspace{0.15cm} invertieren}\hspace{0.05cm}; }[/math]
- [math]\displaystyle{ \underline{s} \hspace{-0.15cm} = \hspace{-0.15cm}(0, 1, 0)\hspace{0.10cm} \Rightarrow\hspace{0.10cm} p_2{\rm \hspace{0.15cm} invertieren}\hspace{0.05cm};\hspace{0.82cm}\underline{s} = (1, 1, 0)\hspace{0.10cm} \Rightarrow\hspace{0.10cm} u_3{\rm \hspace{0.15cm} invertieren}\hspace{0.05cm}; }[/math]
- [math]\displaystyle{ \underline{s} \hspace{-0.15cm} = \hspace{-0.15cm}(0, 1, 1)\hspace{0.10cm} \Rightarrow\hspace{0.10cm} u_4{\rm \hspace{0.15cm} invertieren}\hspace{0.05cm};\hspace{0.82cm}\underline{s} = (1, 1, 1)\hspace{0.10cm} \Rightarrow\hspace{0.10cm} u_2{\rm \hspace{0.15cm} invertieren}\hspace{0.05cm}. }[/math]
Verallgemeinerung der Syndromdecodierung (1)
Wir fassen die Ergebnisse der letzten Seiten zusammen, wobei wir weiterhin vom BSC–Kanalmodell ausgehen. Das bedeutet: y und e sind Elemente von GF(2n), während die möglichen Codeworte xi zum Code C gehören, der einen (n – k)–dimensionalen Untervektorraum von GF(2n) darstellt. Dann gilt:
- Die Syndromdecodierung ist eine Realisierungsmöglichkeit der Maximum–Likelihood–Detektion von Blockcodes. Man entscheidet sich für das Codewort mit der geringsten Hamming–Distanz zum Empfangswort:
- [math]\displaystyle{ \underline{z} = {\rm arg} \min_{\underline{x}_{\hspace{0.03cm}i} \hspace{0.05cm} \in \hspace{0.05cm} \mathcal{C}} \hspace{0.1cm} d_{\rm H}(\underline{y} \hspace{0.05cm}, \hspace{0.1cm}\underline{x}_{\hspace{0.03cm}i})\hspace{0.05cm}. }[/math]
- Die Syndromdecodierung ist aber auch die Suche nach dem wahrscheinlichsten Fehlervektor e, der die Bedingung e · HT = s erfüllt. Das Syndrom liegt dabei durch s = y · HT fest.
- Mit dem Hamming–Gewicht wH(e) kann die zweite Interpretation auch wie folgt mathematisch formuliert werden:
- [math]\displaystyle{ \underline{z} = \underline{y} + {\rm arg} \min_{\underline{e}_{\hspace{0.03cm}i} \hspace{0.05cm} \in \hspace{0.05cm} {\rm GF}(2^n)} \hspace{0.1cm} w_{\rm H}(\underline{e}_{\hspace{0.03cm}i})\hspace{0.05cm}. }[/math]
Zu beachten ist, dass der Fehlervektor e ebenso wie der Empfangsvektor y ein Element von GF(2n) ist im Gegensatz zum Syndrom s ∈ GF(2m) mit der Anzahl m = n – k der Prüfgleichungen. Das bedeutet,
- dass die Zuordnung zwischen Syndrom s und Fehlervektor e nicht eindeutig ist, sondern
- dass jeweils 2k Fehlervektoren zum gleichen Syndrom s führen, die man zu einer Nebenklasse (englisch: Coset) zusammenfasst.

Die Grafik verdeutlicht diesen Sachverhalt am Beispiel n = 5 und k = 2 ⇒ m = n – k = 3.
- Die insgesamt 2n = 32 möglichen Fehlervektoren e werden in 2m = 8 Nebenklassen Ψ0, ... , Ψ7 aufgeteilt, auch „Cosets” genannt. Explizit gezeichnet sind hier nur die Cosets Ψ0 und Ψ5.
- Alle 2k = 4 Fehlervektoren des Cosets Ψμ führen zum gleichen Syndrom sμ. Zudem hat jede Nebenklasse einen Anführer eμ, nämlich denjenigen mit dem minimalen Hamming–Gewicht.
Die Vorgehensweise bei der Syndromdecodierung wird auf den nächsten Seiten nochmals ausführlich an einem Beispiel erläutert.
Verallgemeinerung der Syndromdecodierung (2)
Die Syndromdecodierung wird hier am Beispiel eines systematischen (5, 2, 3)–Codes beschrieben:
- [math]\displaystyle{ \mathcal{C} = \{ (0, 0, 0, 0, 0) \hspace{0.05cm},\hspace{0.15cm}(0, 1, 0, 1, 1) \hspace{0.05cm},\hspace{0.15cm}(1, 0, 1, 1, 0) \hspace{0.05cm},\hspace{0.15cm}(1, 1, 1, 0, 1) \}\hspace{0.05cm}. }[/math]
Generatormatrix und Prüfmatrix lauten:
- [math]\displaystyle{ { \boldsymbol{\rm G}} = \begin{pmatrix} 1 &0 &1 &1 &0 \\ 0 &1 &0 &1 &1 \end{pmatrix} \hspace{0.05cm}, \hspace{0.4cm} { \boldsymbol{\rm H}} = \begin{pmatrix} 1 &0 &1 &0 &0 \\ 1 &1 &0 &1 &0 \\ 0 &1 &0 &0 &1 \end{pmatrix} \hspace{0.05cm}. }[/math]
Die Tabelle fasst das Endergebnis zusammen.

Zur Herleitung dieser Tabelle ist anzumerken:
- Die Zeile 1 bezieht sich auf das Syndrom s0 = (0, 0, 0) und die dazugehörige Nebenklasse Ψ0. Am wahrscheinlichsten ist hier die Fehlerfolge (0, 0, 0, 0, 0) ⇒ kein Bitfehler, die wir als Nebenklassenanführer e0 bezeichnen. Auch die weiteren Einträge in der ersten Zeile, nämlich (1, 0, 1, 1, 0 ), (0, 1, 0, 1, 1) und (1, 1, 1, 0, 1 ), liefern jeweils das Syndrom s0 = (0, 0, 0), ergeben sich aber nur mit mindestens drei Bitfehlern und sind entsprechend unwahrscheinlich.
- In den Zeilen 2 bis 6 beinhaltet der jeweilige Nebenklassenanführer eμ genau eine einzige Eins. Dementsprechend ist eμ stets das wahrscheinlichste Fehlermuster der Klasse Ψμ (μ = 1, ... , 5). Die „Mitläufer” ergeben sich erst bei mindestens zwei Übertragungsfehlern.
- Das Syndrom s6 = (1, 0, 1) ist mit nur einem Bitfehler nicht möglich. Bei der Erstellung obiger Tabelle wurden daraufhin alle „5 über 2” = 10 Fehlermuster e mit Gewicht wH(e) = 2 betrachtet. Die zuerst gefundene Folge mit Syndrom s6 = (1, 0, 1) wurde als e6 = (1, 1, 0, 0, 0) ausgewählt. Bei anderer Probierreihenfolge hätte sich auch die Folge (0, 0, 1, 0, 1) aus Ψ6 ergeben können.
- Ähnlich wurde bei der Bestimmung des Anführers e7 = (0, 1, 1, 0, 0) der Nebenklasse Ψ7 vorgegangen, die durch das einheitliche Syndrom s7 = (1, 1, 1) gekennzeichnet ist. Auch in der Klasse Ψ7 gibt es eine weitere Folge mit Hamming–Gewicht wH(e) = 2, nämlich (1, 0, 0, 0, 1).
Die Beschreibung wird auf der nächsten Seite fortgesetzt.
Verallgemeinerung der Syndromdecodierung (3)
Das Beispiel der letzten Seite wird fortgesetzt. Beachten Sie bitte bei der Tabelle, dass der Index μ nicht identisch ist mit dem Binärwert von sμ. Die Reihenfolge ergibt sich vielmehr durch die Anzahl der Einsen im Nebenklassenanführer eμ. So ergibt sich beispielsweise das Syndrom s5 zu (1, 1, 0) und das Syndrom s6 = (1, 0, 1).

Die obige Tabelle muss nur einmal erstellt und kann beliebig oft genutzt werden. Lautet beispielsweise der Empfangsvektor y = (0, 1, 0, 0, 1), so muss zunächst das Syndrom ermittelt werden:
- [math]\displaystyle{ \underline{s} = \underline{y} \cdot { \boldsymbol{\rm H}}^{\rm T} = \begin{pmatrix} 0 &1 &0 &0 &1 \end{pmatrix} \cdot \begin{pmatrix} 1 &1 &0 \\ 0 &1 &1 \\ 1 &0 &0 \\ 0 &1 &0 \\ 0 &0 &1 \\ \end{pmatrix} = \begin{pmatrix} 0 &1 &0 \end{pmatrix}= \underline{s}_2 \hspace{0.05cm}. }[/math]
Mit dem Nebenklassenanführer e2 = (0, 0, 0, 1, 0) aus obiger Tabelle (roter Eintrag für Index 2) gelangt man schließlich zum Decodierergebnis:
- [math]\displaystyle{ \underline{z} = \underline{y} + \underline{e}_2 = (0,\hspace{0.05cm} 1,\hspace{0.05cm} 0,\hspace{0.05cm} 0,\hspace{0.05cm} 1) + (0,\hspace{0.05cm} 0,\hspace{0.05cm} 0,\hspace{0.05cm} 1,\hspace{0.05cm} 0) = (0,\hspace{0.05cm} 1,\hspace{0.05cm} 0,\hspace{0.05cm} 1,\hspace{0.05cm} 1) \hspace{0.05cm}. }[/math]
Aus dieser Kurzzusammenfassung geht schon hervor, dass die Syndromdecodierung mit einem enormen Aufwand verbunden ist, wenn man nicht wie bei zyklischen Codes gewisse Eigenschaften nutzen kann. Bei großen Blockcodelängen versagt diese Methode vollständig. So müsste man zur Decodierung eines BCH–Codes – die Abkürzung steht für deren Erfinder Bose, Chaudhuri und Hocquenghem – mit den Codeparametern n = 511, k = 259 und dmin = 61 genau 2511–259 ≈ 1076 Fehlermuster der Länge 511 auswerten und abspeichern. Für diese Codes und auch für andere Codes großer Blocklänge gibt es aber spezielle Decodieralgorithmen, die mit weniger Aufwand zum Erfolg führen.
Codiergewinn – Bitfehlerrate bei AWGN
Wir betrachten nun die Bitfehlerrate (englisch: Bit Error Rate, BER) für folgende Konstellationen:
- Hamming–Code (7, 4, 3),
- AWGN–Kanal, gekennzeichnet durch den Quotienten EB/N0 (in dB),
- Maximum–Likelihood–Detektion (ML) mit Hard Decision bzw. Soft Decision.
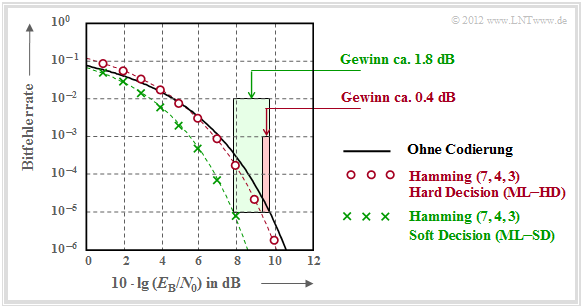
Bitfehlerrate bei (7, 4, 3)–Hamming–Codierung

Zu dieser Grafik ist anzumerken:
- Die schwarze Vergleichskurve gilt beispielsweise für die binäre Phasenmodulation (BPSK) ohne Codierung. Hierfür benötigt man für die Bitfehlerrate 10–5 etwa 10 · lg EB/N0 ≈ 9.6 dB.
- Die roten Kreise gelten für den (7, 4, 3)–Code und harte Entscheidungen des ML–Decoders (ML–HD). Die Syndromdecodierung ist hierfür eine mögliche Realisierungsform.
- Diese Systemkonfiguration bringt erst für 10 · lg EB/N0 > 6 dB eine Verbesserung gegenüber dem Vergleichssystem. Für BER = 10–5 benötigt man nur noch 10 · lg EB/N0 ≈ 9.2 dB.
- Die grünen Kreuze für den Hamming–Code mit Soft–Decision (ML–SD) liegen im gesamten Bereich unterhalb der Vergleichskurve. Für BER = 10–5 ergibt sich 10 · lg (EB/N0) ≈ 7.8 dB.
- [math]\displaystyle{ G_{\rm Code} (\hspace{0.05cm}{\rm System}\hspace{0.05cm}|\hspace{0.05cm}{\rm BER}\hspace{0.05cm}) = }[/math]
- [math]\displaystyle{ = 10 \cdot {\rm lg}\hspace{0.1cm}{E}_{\rm B}/N_0 \hspace{0.15cm}(\hspace{0.05cm}{\rm ohne\hspace{0.1cm} Codierung}\hspace{0.05cm}|\hspace{0.05cm}{\rm BER}\hspace{0.05cm})- 10 \cdot {\rm lg}\hspace{0.1cm}{E}_{\rm B}/N_0 \hspace{0.15cm}(\hspace{0.05cm}{\rm System}\hspace{0.05cm}|\hspace{0.05cm}{\rm BER}\hspace{0.05cm}) \hspace{0.05cm}. }[/math]
Angewendet auf obige Grafik erhält man:
- [math]\displaystyle{ G_{\rm Code} (\hspace{0.05cm}{\rm Hamming \hspace{0.1cm}(7,\hspace{0.02cm}4,\hspace{0.02cm}3), ML-HD}\hspace{0.05cm}|\hspace{0.05cm}{\rm BER} = 10^{-5}\hspace{0.05cm}) = 0.4\,{\rm dB}\hspace{0.05cm}, }[/math]
- [math]\displaystyle{ G_{\rm Code} (\hspace{0.05cm}{\rm Hamming \hspace{0.1cm}(7,\hspace{0.02cm}4,\hspace{0.02cm}3), ML-SD}\hspace{0.05cm}|\hspace{0.05cm}{\rm BER} = 10^{-5}\hspace{0.05cm}) = 1.8\,{\rm dB}\hspace{0.05cm}. }[/math]
Decodierung beim Binary Erasure Channel (1)
Abschließend soll noch gezeigt werden, in wie weit der Decoder zu modifizieren ist, wenn anstelle des BSC–Modells (Binary Symmetrie Channel) das BEC–Kanalmodell (Binary Erasure Channel) zum Einsatz kommt, der keine Fehler produziert, sondern unsichere Bit als Auslöschungen markiert.
 Nebenstehende Grafik zeigt das Systemmodell und gibt beispielhafte Werte für die einzelnen Vektoren wider. Der linke Bildteil (blau hinterlegt) gilt für das BSC–Modell (ein Bitfehler 0 → 1) und der rechte (grün hinterlegt) für das BEC–Modell (zwei Erasures 1 → E).
Nebenstehende Grafik zeigt das Systemmodell und gibt beispielhafte Werte für die einzelnen Vektoren wider. Der linke Bildteil (blau hinterlegt) gilt für das BSC–Modell (ein Bitfehler 0 → 1) und der rechte (grün hinterlegt) für das BEC–Modell (zwei Erasures 1 → E).
Ohne Einschränkung der Allgemeingültigkeit betrachten wir wie im Beispiel auf Seite 3c dieses Kapitels wieder den systematischen (5, 2, 3)–Blockcode mit den vier Codeworten
- [math]\displaystyle{ \mathcal{C} = \{ (0, 0, 0, 0, 0) \hspace{0.05cm},\hspace{0.15cm}(0, 1, 0, 1, 1) \hspace{0.05cm},\hspace{0.15cm}(1, 0, 1, 1, 0) \hspace{0.05cm},\hspace{0.15cm}(1, 1, 1, 0, 1) \}\hspace{0.05cm}. }[/math]
Man erkennt:
- Bei BSC kann wegen dmin = 3 nur ein Bitfehler (t = 1) korrigiert werden (rot markiert). Beschränkt man sich auf Fehlererkennung, so funktioniert diese bis zu e = dmin – 1 = 2 Bitfehler.
- Bei BEC macht Fehlererkennung keinen Sinn, denn bereits der Kanal lokalisiert ein unsicheres Bit als Erasure E (Auslöschung). Die Nullen und Einsen im BEC–Empfangswort y sind sicher. Deshalb funktioniert hier die Fehlerkorrektur bis zu e = 2 Auslöschungen mit Sicherheit.
- Auch e = 3 Auslöschungen sind manchmal noch korrigierbar. So kann y = (E, E, E, 1, 1) zu z = (0, 1, 0, 1, 1) korrigiert werden, da kein zweites Codewort mit zwei Einsen endet. Dagegen ist y = (0, E, 0, E, E) aufgrund des im Code erlaubten Nullwortes nicht korrigierbar.
- Wird sichergestellt, dass in keinem Empfangswort mehr als zwei Auslöschungen vorkommen, so ist die BEC–Blockfehlerwahrscheinlichkeit Pr(z ≠ x) = Pr(υ ≠ u) identisch 0. Dagegen ist die entsprechende Blockfehlerwahrscheinlichkeit beim BSC–Modell stets größer als 0.
Da nach dem BEC ein jedes Empfangswort entweder richtig oder gar nicht decodiert wird, nennen wir hier den Block y → z zukünftig „Codewortfinder”. Eine „Schätzung” findet nur beim BSC–Modell statt.
Decodierung beim Binary Erasure Channel (2)
Wie funktioniert aber nun die Decodierung eines Empfangswortes y mit Auslöschungen algorithmisch? Ausgehend vom Empfangswort y = (0, E, 0, E, 1) des letzten Beispiels setzen wir den Ausgang des Codewortfinders formal zu z = (0, z2, 0, z4, 1), wobei die Symbole z2 und z4 (jeweils 0 oder 1) entsprechend der folgenden Gleichung zu bestimmen sind:
- [math]\displaystyle{ \underline{z} \cdot { \boldsymbol{\rm H}}^{\rm T}= \underline{0} \hspace{0.3cm} \Rightarrow \hspace{0.3cm} { \boldsymbol{\rm H}} \cdot \underline{z}^{\rm T}= \underline{0}^{\rm T} \hspace{0.05cm}. }[/math]
Es geht nun darum, diese Bestimmungsgleichung möglichst effizient umzusetzen.
- Mit der Prüfmatrix H des (5, 2, 3)–Blockcodes und dem Vektor z = (0, z2, 0, z4, 1) lautet die obige Bestimmungsgleichung:
- [math]\displaystyle{ { \boldsymbol{\rm H}} \cdot \underline{z}^{\rm T} = \begin{pmatrix} 1 &0 &1 &0 &0\\ 1 &1 &0 &1 &0\\ 0 &1 &0 &0 &1 \end{pmatrix} \cdot \begin{pmatrix} 0 \\ z_2 \\ 0 \\ z_4 \\ 1 \end{pmatrix} = \begin{pmatrix} 0 \\ 0 \\ 0 \end{pmatrix} \hspace{0.05cm}. }[/math]
- Wir fassen die sicheren (korrekten) Bit zum Vektor zK zusammen und die ausgelöschten Bit zum Vektor zE. Dann teilen wir die Prüfmatrix H in die entsprechenden Teilmatrizen HK und HE auf:
- [math]\displaystyle{ \underline{z}_{\rm K} \hspace{-0.15cm} = \hspace{-0.15cm} (0, 0, 1)\hspace{0.05cm},\hspace{0.3cm} { \boldsymbol{\rm H}}_{\rm K}= \begin{pmatrix} 1 &1 &0\\ 1 &0 &0\\ 0 &0 &1 \end{pmatrix} \hspace{0.3cm}\Rightarrow\hspace{0.3cm} {\rm Spalten\hspace{0.15cm} 1,\hspace{0.15cm}3 \hspace{0.15cm}und \hspace{0.15cm}5 \hspace{0.15cm}der \hspace{0.15cm}Pr\ddot{u}fmatrix} \hspace{0.05cm}, }[/math]
- [math]\displaystyle{ \underline{z}_{\rm E} \hspace{-0.15cm} = \hspace{-0.15cm} (z_2, z_4)\hspace{0.05cm},\hspace{0.35cm} { \boldsymbol{\rm H}}_{\rm E}= \begin{pmatrix} 0 &0\\ 1 &1\\ 1 &0 \end{pmatrix} \hspace{0.9cm}\Rightarrow\hspace{0.3cm} {\rm Spalten\hspace{0.15cm} 2 \hspace{0.15cm}und \hspace{0.15cm}4 \hspace{0.15cm}der \hspace{0.15cm}Pr\ddot{u}fmatrix} \hspace{0.05cm}. }[/math]
- Unter Berücksichtigung der Tatsache, dass in GF(2) die Subtraktion gleich der Addition ist, lässt sich die obige Gleichung wie folgt darstellen:
- [math]\displaystyle{ { \boldsymbol{\rm H}}_{\rm K} \cdot \underline{z}_{\rm K}^{\rm T} + { \boldsymbol{\rm H}}_{\rm E} \cdot \underline{z}_{\rm E}^{\rm T}= \underline{0}^{\rm T} \hspace{0.3cm} \Rightarrow \hspace{0.3cm} { \boldsymbol{\rm H}}_{\rm E} \cdot \underline{z}_{\rm E}^{\rm T}= { \boldsymbol{\rm H}}_{\rm K} \cdot \underline{z}_{\rm K}^{\rm T} }[/math]
- [math]\displaystyle{ \Rightarrow \hspace{0.3cm} \begin{pmatrix} 0 &0\\ 1 &1\\ 1 &0 \end{pmatrix} \cdot \begin{pmatrix} z_2 \\ z_4 \end{pmatrix} = \begin{pmatrix} 1 &1 &0\\ 1 &0 &0\\ 0 &0 &1 \end{pmatrix} \cdot \begin{pmatrix} 0 \\ 0 \\ 1 \end{pmatrix} = \begin{pmatrix} 0 \\ 0 \\ 1 \end{pmatrix} \hspace{0.05cm}. }[/math]
- Dies führt zu einem linearen Gleichungssystem mit zwei Gleichungen für die beiden unbekannten z2 und z4 (jeweils 0 oder 1). Aus der letzten Zeile erhält man z2 = 1 und aus der zweiten Zeile folgt somit z2 + z4 = 0 ⇒ z4 = 1. Damit ergibt sich das zulässige Codewort z = (0, 1, 0, 1, 1).
Aufgaben zum Kapitel
Zusatzaufgaben:1.11 Nochmals Syndromdecodierung
Zusatzaufgaben:1.12 Vergleich (7, 4, 3) und (8, 4, 4)
Zusatzaufgaben:1.13 Nochmals BEC–Decodierung