Burrows–Wheeler–Transformation $\rm (BWT)$ gemäß der Beschreibung in Aufgabe 2.13; die beiden Zeichenmengen am Eingang und Ausgang des BWT sind gleich: $\{$ $\rm D$, $\rm E$, $\rm I$, $\rm M$, $\rm N$, $\rm S$ $\}$;
Move–to–Front $\rm (MTF)$, ein Sortieralgorithmus, der eine gleich lange Zeichenfolge $($im Beispiel $N = 12)$, aber mit anderem Alphabet $\{$0, 1, 2, 3, 4, 5$\}$ ausgibt;
$\rm RLC0$ – eine Lauflängencodierung speziell für die nach $\rm BWT$ und $\rm MTF$ (möglichst) häufige Null; alle anderen Indizes werden durch $\rm RLC0$ nicht verändert;
$\rm Huffman$ gemäß der Beschreibung im Kapitel Entropiecodierung nach Huffman; häufige Zeichen werden durch kurze Binärfolgen dargestellt und seltene durch lange.
Der $\rm MTF$–Algorithmus lässt sich bei $M = 6$ Eingangssymbolen wie folgt beschreiben:
Die Ausgangsfolge des $\rm MTF$ ist eine Aneinanderreihung von Indizes aus der Menge
$ I = \{$0, 1, 2, 3, 4, 5$\}$.
Vor Beginn des eigentlichen $\rm MTF$–Algorithmus werden die möglichen Eingangssymbole lexikografisch sortiert und den folgenden Indizes zugeordnet:
Der $\rm MTF$–Eingabestring sei hier $\rm N\hspace{0.05cm}M\hspace{0.05cm}S\hspace{0.05cm}D\hspace{0.05cm}E\hspace{0.05cm}E\hspace{0.05cm}E\hspace{0.05cm}N\hspace{0.05cm}I\hspace{0.05cm}I\hspace{0.05cm}I\hspace{0.05cm}N$. Dies war das $\rm BWT$–Ergebnis in der Aufgabe 2.13. Das erste $\rm N$ wird gemäß Voreinstellung mit $I = 4$ dargestellt.
Anschließend wird das $\rm N$ in der Sortierung an den Anfang gestellt, so dass nach dem Codierschritt $i = 1$ die Zuordnung gilt:
In gleicher Weise fährt man fort, bis der gesamte Eingangstext abgearbeitet ist. Steht ein Zeichen bereits an Position 0, so ist keine Neusortierung erforderlich.
Informationen zum Huffman–Code finden Sie im Kapitel Entropiecodierung nach Huffman. Für die Lösung der Aufgabe sind diese Informationen nicht erforderlich.
(1) Die Grafik auf der Angabenseite zeigt, dass die Lösungsvorschläge 1 und 2 richtig sind und der Vorschlag 3 falsch ist:
$\rm E$ und $\rm I$ treten zwar gruppiert auf,
aber nicht die $\rm N$–Zeichen.
(2) Richtig sind die Lösungsvorschläge 2 und 3:
Die Eingangsfolge wird Zeichen für Zeichen abgearbeitet. Auch die Ausgangsfolge hat somit die Länge $N = 12$.
Tatsächlich wird die Eingangsmenge $\{ \hspace{0.05cm}\rm D,\hspace{0.05cm} E,\hspace{0.05cm} I,\hspace{0.05cm} M,\hspace{0.05cm} N , \hspace{0.05cm} S \}$ in die Ausgangsmenge $\{ \hspace{0.05cm}\rm 0,\hspace{0.05cm} 1,\hspace{0.05cm} 2,\hspace{0.05cm} 3,\hspace{0.05cm} 4 , \hspace{0.05cm} 5 \}$ gewandelt.
Allerdings nicht durch einfaches Mapping, sondern durch einen Algorithmus, der nachfolgend skizziert wird.
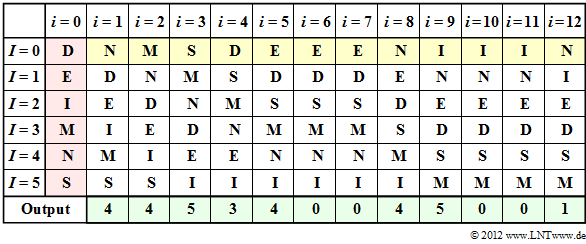
Beispiel für den MTF–Algorithmus
(3) Richtig ist der Lösungsvorschlag 2:
Die Tabelle zeigt den MTF–Algorithmus. Der Schritt $i=0$ (rote Hinterlegung) gibt die Vorbelegung an. Die Eingabe der MTF ist gelb hinterlegt, die Ausgabe grün.
Im Schritt $i=1$ wird das Eingangszeichen $\rm N$ entsprechend der Spalte $i=0$ durch den Index $I = 4$ dargestellt. Anschließend wird $\rm N$ nach vorne sortiert, während die Reihenfolge der anderen Zeichen gleich bleibt.
Das Eingangszeichen $\rm M$ im zweiten Schritt erhält entsprechend der Spalte $i=2$ ebenfalls den Index $I = 4$. In gleicher Weise macht man weiter bis zum zwölften Zeichen $\rm N$, dem der Index $I = 1$ zugeordnet wird.
Man erkennt aus obiger Tabelle weiter, dass zu den Zeitpunkten $i=6$, $i=7$, $i=10$ und $i=11$ der Ausgabeindex jeweils $I = 0$ ist.
(4) Richtig sind die Aussagen 1 und 2:
Die Vorverarbeitungen "BWT" und "MTF" haben nur die Aufgabe, möglichst viele Nullen zu generieren.
(5)Alle Aussagen sind richtig.
Nähere Angaben zum Huffman–Algorithmus finden Sie im Kapitel "Entropiecodierung nach Huffman".